

This post will cover the most important content of a 2bit file: the actual sequence data itself. In the first post I wrote about the format of the file's header, and in the second post I wrote about the content of the file's index.
At this point that's enough information to know what's in the file and where to find it. In other words we know the list of sequences that live in the file, and we know where each one is positioned within the file. So, assuming we have our index in memory (ideally some sort of key/value store of sequences names and their offsets in the file), given the name of a sequence we can know where to go in the file to load up the data.
So the next obvious question is, what will we find when we get there? Actual sequence data is stored like this:
| Content | Type | Size | Comments |
| DNA size | Integer | 4 bytes | Count of bases in the sequence |
| N block count | Integer | 4 bytes | Count of N blocks in the sequence |
| N block starts | Integer Array | 4*count bytes | Positions are zero-based |
| N block sizes | Integer Array | 4*count bytes | |
| Mask block count | Integer | 4 bytes | Count of mask blocks in the sequence |
| Mask block starts | Integer Array | 4*count bytes | Positions are zero-based |
| Mask block sizes | Integer Array | 4*count bytes | |
| Reserved | Integer | 4 bytes | Should always be 0 |
| DNA data | Byte Array | See below |
Breaking the above down:
N blocks
As mentioned in passing in the first post: technically it's necessary to encode 5 different characters for the bases in the sequences. As well as the usual T, C, A and G, there also needs to be an N, which means the base is unknown. Now, of course, you can't pack 5 states into two bits, so the 2bit file format solves this by having an array of block positions and sizes where any data in the actual DNA itself should be ignored and an N used in its place.
Mask blocks
This is where my ignorance of bioinformatics shows, and where it's made very obvious that I'm a software developer who likes to muck about with data and data structures, but who doesn't always understand why they're used. I'm actually not sure what purpose mask blocks serve in a 2bit file, but they do affect the output. If a base falls within a mask block the value that is output should be a lower-case letter, rather then upper-case.
The DNA data
So this is the fun bit, where the real data is stored. This should be viewed as a sequence of bytes, each of which contains 4 bases (except for the last byte, of course, which might contain 1, 2 or 3 depending on the size of the sequence).
Each byte should be viewed as an array of 2 bit values, with the values mapping like this:
| Binary | Decimal | Base |
| 00 | 0 | T |
| 01 | 1 | C |
| 10 | 2 | A |
| 11 | 3 | G |
So, given a byte whose value is 27, you're looking at the sequence TCAG. This is because 27 in binary is 00011011, which breaks down as:
| 00 | 01 | 10 | 11 |
| T | C | A | G |
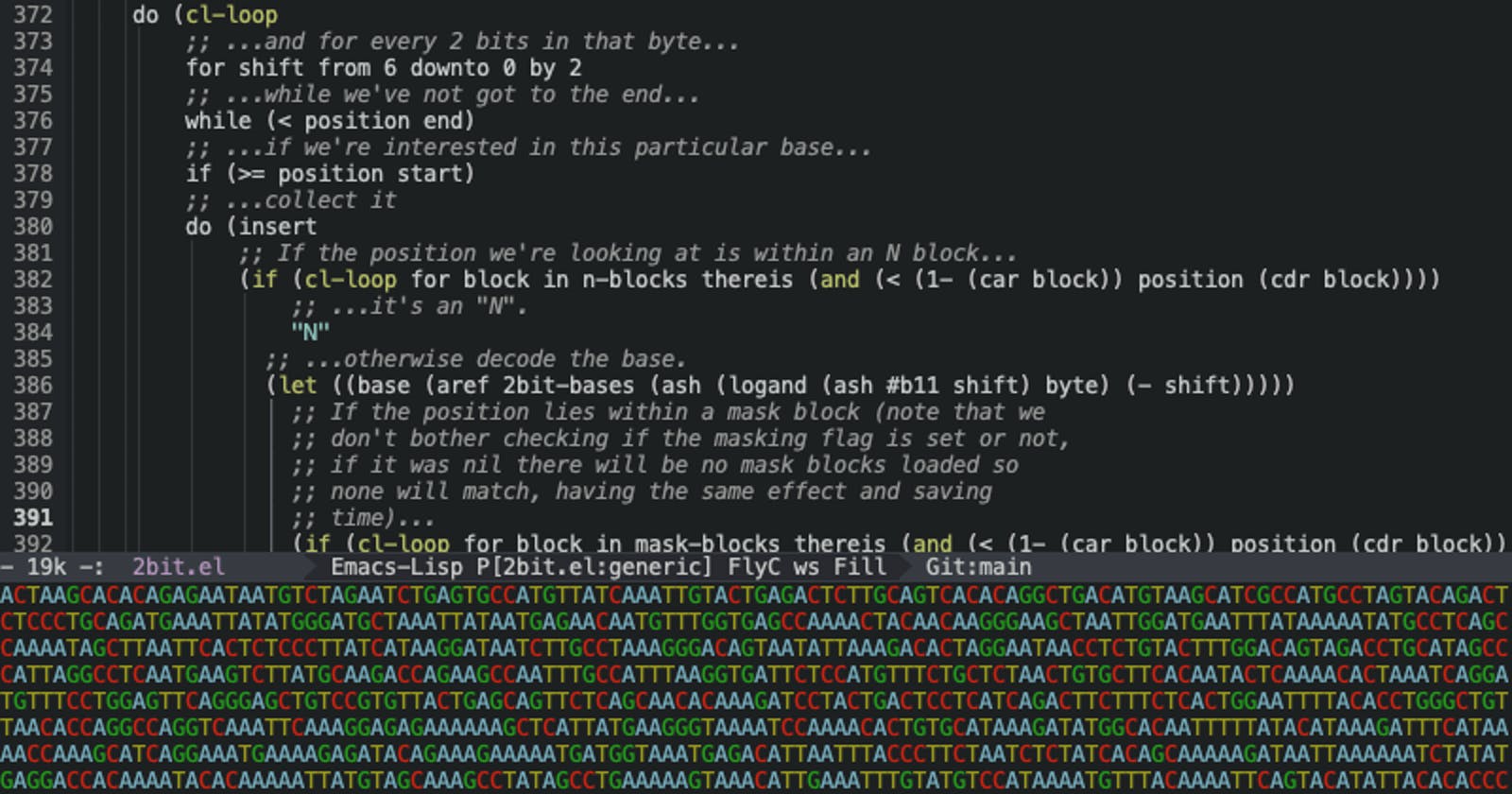
How you pull that data out of the byte will depend on the language and what it makes available for bit-twiddling; those that don't have some form of bit field will probably provide the ability to bit shift and do a bitwise and (it's also likely that doing bitwise operations is better than using bit fields anyway). In the version I wrote in Emacs Lisp, it's simply a case of shifting the two bits I am interested in over to the right of the byte and then performing a bitwise and to get just its value. So, given an array called 2bit-bases whose content is this:
(defconst 2bit-bases ["T" "C" "A" "G"]
"Vector of the bases.
Note that the positions of each base in the vector map to the 2bit decoding
for them.")
I use this bit of code to pull out the individual bases:
(aref 2bit-bases (logand (ash byte (- shift)) #b11))
Given code to unpack an individual byte, extracting all of the bases in a sequence then becomes the act of having two loops, the outer loop being over each byte in the file, the inner loop being over the positions within each individual byte.
In pseudo-code, assuming that start and end hold the base locations we're interested in and dna_pos is the location in the file where the DNA starts, the main loop for unpacking the data looks something like this:
# The bases.
bases = [ "T", "C", "A", "G" ]
# Calculate the first and last byte to pull data from.
start_byte = dna_pos + floor( start / 4 )
end_byte = dna_pos + floor( ( end - 1 ) / 4 )
# Work out the starting position.
position = ( start_byte - dna_pos ) * 4
# Load up the bytes that contain the DNA.
buffer = read_n_bytes_from( start_byte, ( end_byte - start_byte ) + 1 )
# Get all the N blocks that intersect this sub-sequence.
n_blocks = relevant_n_blocks( start, end )
# Get all the mask blocks that interest this sub-sequence.
mask_blocks = relevant_mask_blocks( start, end )
# Start with an empty sequence.
sequence = ""
# Loop over every byte in the buffer.
for byte in buffer
# Stepping down each pair of bits in the byte.
for shift from 6 downto 0 by 2
# If we're interested in this location.
if ( position >= start ) and ( position < end )
# If this position is in an N block, just collect an N.
if within( position, n_blocks )
sequence = sequence + "N"
else
# Not a N, so we should decode the base.
base = bases[ ( byte >> shift ) & 0b11 ]
# If we're in a mask block, go lower case.
if within( position, mask_blocks )
sequence = sequence + lower( base )
else
sequence = sequence + base
end
end
end
# Move along.
position = position + 1
end
end
Note that some of the detail is left out in the above, especially the business of loading up the relevant blocks; how that would be done will depend on language and the approach to writing the code. The Emacs Lisp code I've written has what I think is a fairly straightforward approach to it. There's a similar approach in the Common Lisp code I've written.
And that's pretty much it. There are a few other details that differ depending on how this is approached, the language used, and other considerations; one body of 2bit reader code that I've written attempts to optimise how it does things as much as possible because it's capable of reading the data locally or via ranged HTTP GETs from a web server; the Common Lisp version I wrote still needs some work because I was having fun getting back into Common Lisp; the Emacs Lisp version needs to try and keep data as small as possible because it's working with buffers, not direct file access.
Having got to know the format of 2bit files a fair bit, I'm adding this to my list of "fun to do a version of" problems when getting to know a new language, or even dabbling in a language I know.